OpenTally dev log: Battery of optimisations leads to 108% performance improvement
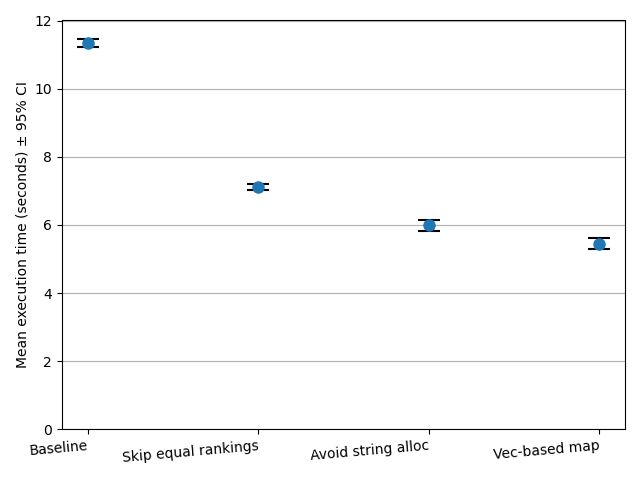
Using rational arithmetic, OpenTally e825ca1 processes the 3,821,539-vote 2022 Australian Senate election for Victoria in a mean 11.34 (95% CI ± 0.03) seconds on my Intel i5-7500. This week I put some time into cutting this figure down.
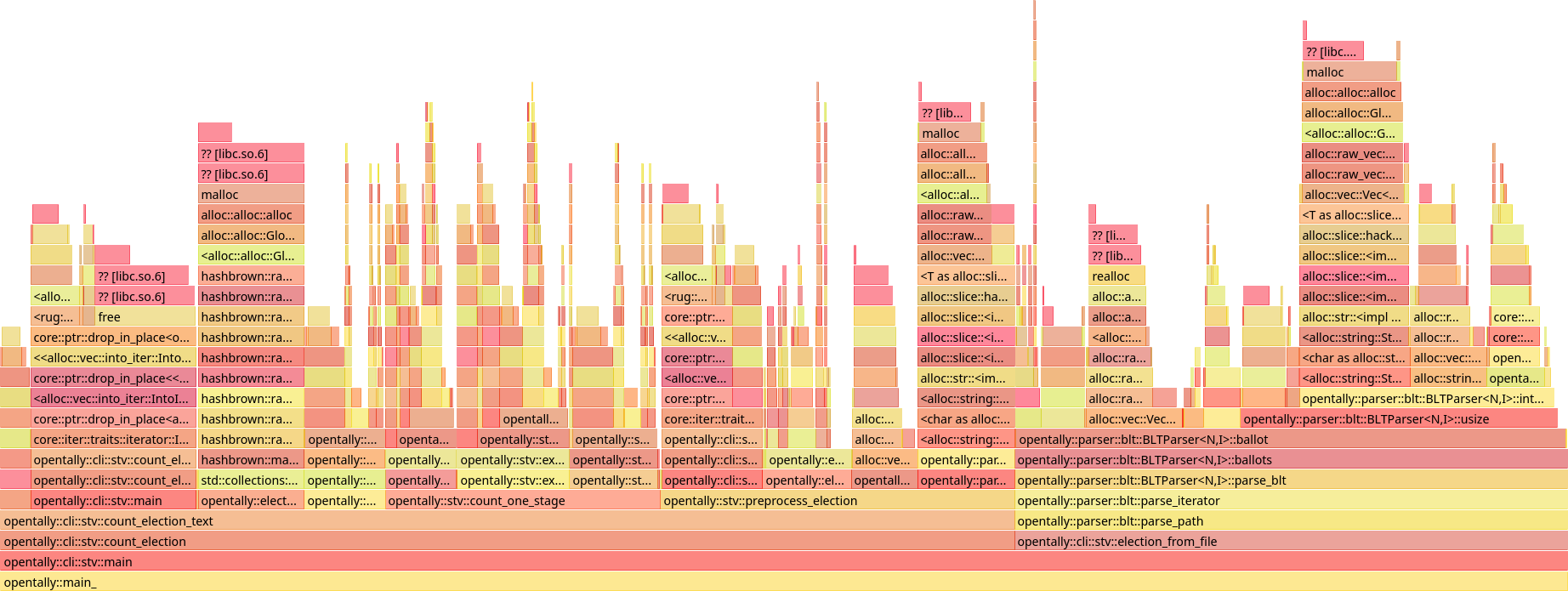
Using perf and Hotspot, we obtain the following flamegraph:
Opportunistically skip an expensive no-op
4.7% of total execution time is spent in Election::realise_equal_rankings, which is responsible for processing ballots with multiple candidates preferenced at the same level. This is surprising, because such a ballot is not permitted under the Australian Senate rules, and so there are no such ballots in this election. The original code iterates over every ballot unconditionally summing the weights, and rebuilds the Vec representing each ballot's preferences one item at a time – an expensive no-op.
The new code (ee7ac06 and 6bb127a) determines at parse time (when this information is readily available) whether the ballot contains equal rankings, so the realise_equal_rankings step can be skipped when no ballots have equal rankings.
This has substantial performance implications, lowering the average execution time to 7.12 (± 0.02) seconds.
Avoiding unnecessary string allocations
We also see that a substantial amount of time (nearly 30%) is actually spent reading the election from file, and a large portion of that (17% of total execution time) is spent in BLTParser::usize reading integers from the file. This is not itself surprising – the election data file consists almost entirely of integers to be read – but what is surprising is that most of the time in this function is spent in string allocation. The relevant code reads:
/// Parse an integer into a [usize]
fn usize(&mut self) -> Result<usize, ParseError> {
return Ok(self.integer()?.parse().expect("Invalid usize"));
}
/// Parse an integer as a [String]
fn integer(&mut self) -> Result<String, ParseError> {
let mut result = String::from(self.digit_nonzero()?);
loop {
match self.digit() {
Err(_) => { break; }
Ok(d) => { result.push(d); }
}
}
return Ok(result);
}
This is an obviously inefficient procedure. We allocate a String and then push characters on to it, one character at a time. This requires memory allocations when the string is first allocated, and additional memory allocations if we must resize the string because there were more characters than expected. To add insult to injury, we do not even use the string in the end, simply converting it to a usize and dropping the string.
An alternative implementation operates directly on usize integers, which do not require heap allocation:
fn usize(&mut self) -> Result<usize, ParseError> {
let mut result = self.digit_nonzero()?.to_digit(10).unwrap() as usize;
loop {
match self.digit() {
Err(_) => { break; }
Ok(d) => {
result = result.checked_mul(10).expect("Integer overflows usize");
result = result.checked_add(d.to_digit(10).unwrap() as usize).expect("Integer overflows usize");
}
}
}
return Ok(result);
}
Despite the additional complexity of checking for overflow on reading each digit, this implementation is much faster on the whole, coming in at an average 5.99 (± 0.03) seconds.
Faster HashMap hash algorithm
Turning to the counting itself, 14.8% of total execution time is spent in stv::next_preferences, i.e. in the distribution of preferences. This is, again, unsurprising on its own, as the distribution of preferences forms the bulk of the count. However, a substantial portion of time is spent inside HashMap-related code. 3.2% of total execution time is spent in HashMap::get, and 2.6% specifically inside Candidate::hash.
The definition of Candidate is as follows:
#[derive(Clone, Eq, Hash, PartialEq)]
pub struct Candidate {
pub name: String,
pub is_dummy: bool,
}
The default derived implementation for Hash is to hash each member of the struct. However, this is quite inefficient, given that HashMaps on Candidates are a major data type in OpenTally, and given that we already have a unique integer index for candidates.
We can add the index to the Candidate struct so it can be easily looked up, and use nohash-hasher to simply use this index as the hash (422a198). Similarly, we can use the index to simplify equality checking on Candidates, which is also used by HashMap (974a56d). Doing so brings the average execution time down to 5.63 (± 0.02) seconds.
Why HashMaps at all?
If we have sequential, small, integer indexes for candidates already, this raises the question of why we are using HashMaps at all. One imagines it would generally be faster to simply use a Vec and perform lookups directly by index. This obviates the need to hash the key, find a bucket for the hash, and check for equality of keys.
The HashMap data type is widely embedded within the OpenTally codebase, so a direct change would be a large undertaking (and very premature without benchmarks!), so candmap.rs implements a mock data structure which mimics the API of a HashMap, but internally uses a Vec. In broad strokes:
/// Mimics a [HashMap] on [Candidate]s, but internally is a [Vec] based on [Candidate::index]
pub struct CandidateMap<'e, V> {
entries: Vec<Option<(&'e Candidate, V)>>
}
impl<'e, V> CandidateMap<'e, V> {
fn maybe_resize(&mut self, len: usize) {
if len < self.entries.len() {
return;
}
self.entries.resize_with(len, || None);
}
pub fn insert(&mut self, candidate: &'e Candidate, value: V) {
self.maybe_resize(candidate.index + 1);
self.entries[candidate.index] = Some((candidate, value));
}
pub fn get(&self, candidate: &'e Candidate) -> Option<&V> {
return self.entries.get(candidate.index).unwrap_or(&None).as_ref().map(|(_, v)| v);
}
// ...
}
This implementation reduces the average execution time to 5.45 (± 0.03) seconds. A marginal improvement now, but compared to the original implementation using default HashMaps, approximately 10% faster.
Comparison graph
The graph below compares the average execution time after each successive optimisation. Error bars are shown at 5× true scale.