Investigating a proprietary early-2000s abandonware ebook format
This article concerns a Windows software product which featured the ability to compile HTML websites and multimedia content into a standalone EXE file. The last release of this product was in 2003, and the product website has ceased to operate from 2012. Content was stored as HTML and rendered within a bundled web browser; however, HTML files and other resources were obfuscated on disk, making it difficult to extract the standard HTML and image content from within this now-defunct proprietary format.
I have been able to locate only one previous attempt at decompiling ebooks from this software. The decompiler itself has been archived by the Internet Archive; however, to extract more than the index HTML file, paid registration was required, which is no longer possible.
This article details a successful effort to reverse engineer the ebook format and extract all source files as standard HTML and image files.
Packed executable
Ebooks from this software are distributed as standalone EXE files. However, examining the EXE file shows only a handful of readable strings, none of which are source file content, or show any signs of the program implementation.
$ strings ebook.exe
This program must be run under Win32
CODE
DATA
.idata
.tls
.rdata
.reloc
.rsrc
.aspack
.data
*^$
{fjdi57
[ii[
[...]
Loading the EXE file into Ghidra reveals only two functions, neither of which is very enlightening.
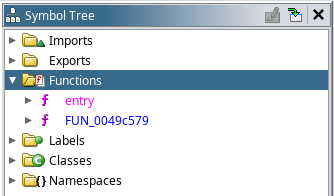
This is due to the EXE file having been processed by a packer, which compresses and simultaneously obfuscates the EXE file contents. The .aspack section header confirms that the ASPack packer was responsible – which is designed to ‘protect [applications] against non-professional reverse engineering’. We shall see how effective this is.
AspackDie is a tool which purportedly can unpack ASPack-packed executables. It was unsuccessful in this case, yielding an executable that could not be executed nor analysed. It is also not open source, and its safety cannot be guaranteed, and so was used only in a virtual machine. However, it did identify trailing data at the end of the EXE file.
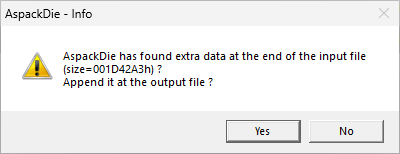
Presumably, this trailing data is the actual content of the ebook; however, inspecting it reveals no human-readable contents, which suggests the data may be encrypted or compressed.
Unpacking the EXE
A successful approach to unpacking the packed EXE is outlined by Abhisek Datta. We can see that the entry point begins with a pushad instruction, which will push all registers onto the stack. Presumably, this will later be followed by a popad instruction to restore the register values before transferring control to the unpacked code at the ‘original entry point' (OEP).
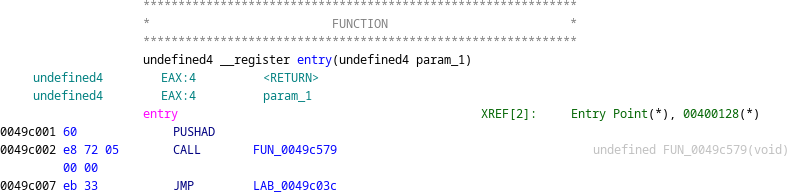
We follow the entry point disassembly to locate a popad instruction, which is followed by some unusual-looking code.
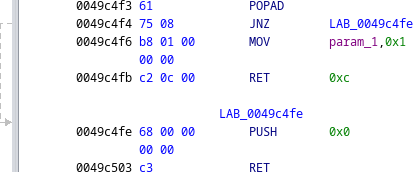
The instructions push 0 followed by ret should result in jumping to the address 0x0, which will clearly be invalid. To investigate further, we can use the debugger in Ghidra to break on the push instruction.1
(gdb)b *0x49c4fe
Breakpoint 1 at 0x49c4fe
(gdb)c
Continuing.
Breakpoint 1, 0x0049c4fe in ?? () from /path/to/ebook.exe
Within the debugger, we can see the code has self-modified so that execution will instead jump to the address 0x47c7a8. This is the OEP.

Having identified the OEP, we can use x32dbg and OllyDumpEx to dump the unpacked executable.
Running the unpacked executable yields an error message that the ebook has an incorrect signature.
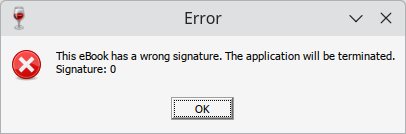
Concatenating the trailing data identified by AspackDie to the end of the unpacked executable allows the ebook to launch as usual. This confirms that the trailing data contains the contents of the ebook, and indicates that some integrity protection is present in the form of a signature.
Recovering symbol names
Importing the unpacked EXE into Ghidra, Ghidra identifies Borland Delphi as the compiler.
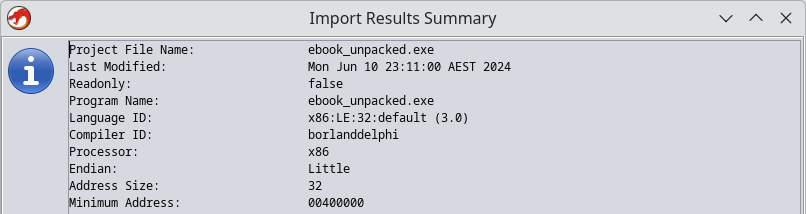
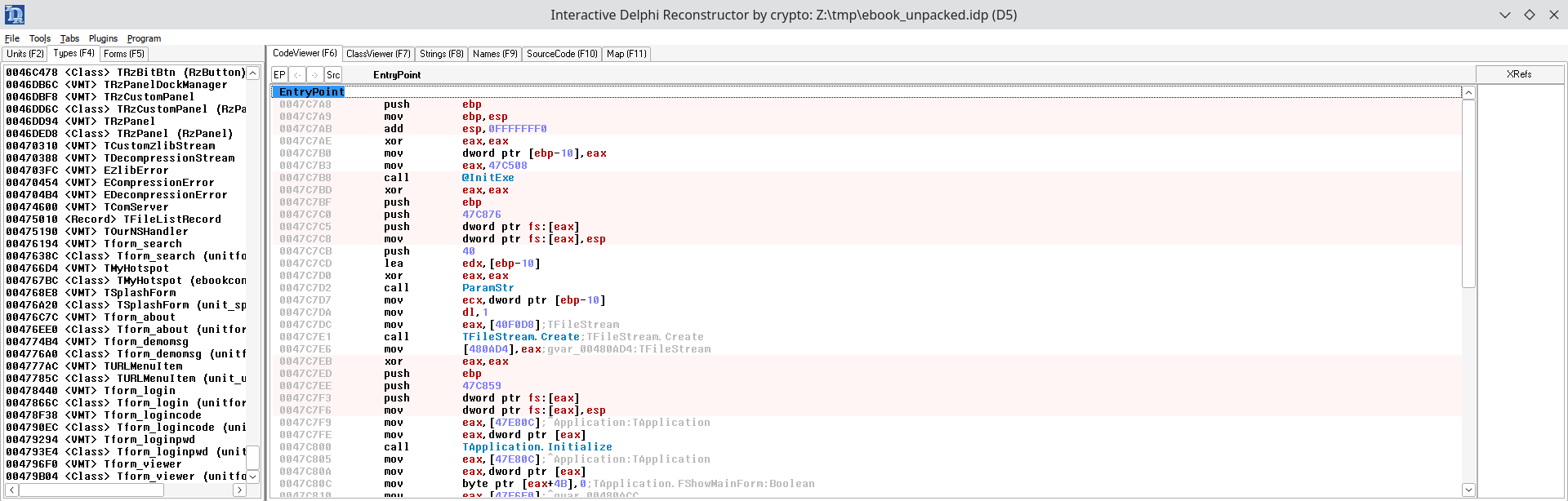
Additional tooling is required to obtain symbol names in Ghidra with Delphi projects – namely, IDR and Dhrake.
According to the Dhrake instructions, we open the executable in IDR to dump the symbols to an IDC file. Incidentally, we notice that the Delphi code contains references to classes called TDecompressionStream, TCustomZlibStream and EZlibError. This suggests that possibly zlib is used to compress the ebook data.
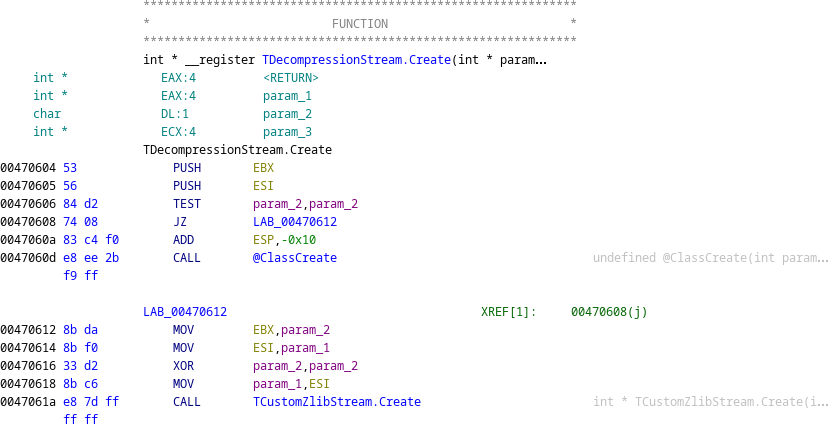
We return to Ghidra to apply Dhrake. The results of Ghidra's auto-analysis are not perfect; for example, the TDecompressionStream.Create function is located by Dhrake but not recognised by Ghidra as code.

Manual intervention is required in these cases to mark the data as code, and create a function.
Dynamic analysis
Proceeding with the hypothesis that the zlib-related classes are used to decompress the ebook contents, we launch the unpacked EXE in a debugger, and set a breakpoint in TDecompressionStream.Create.
(gdb)b *0x470604
Breakpoint 1 at 0x470604
(gdb)c
Continuing.
Thread 1 "060c" hit Breakpoint 1, 0x00470604 in ?? () from /path/to/ebook_unpacked.exe
(gdb)info reg
eax 0x4703d4 4654036
ecx 0x1477434 21460020
edx 0x40f101 4256001
ebx 0x1471c90 21437584
[...]
We note that ecx points to a structure, whose first two members appear to be pointers within memory.
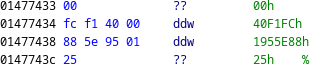
The first pointer, 0x40f1fc, points within the virtual method table (VMT) of TMemoryStream.
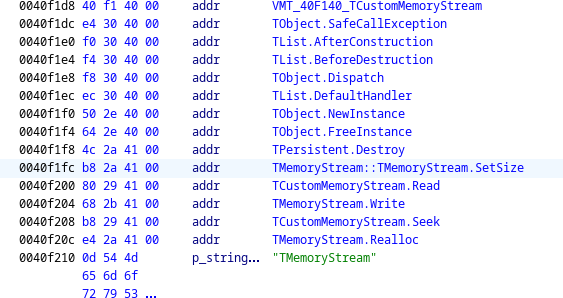
Presumably, then, the second pointer points to the memory region being streamed.
(gdb)x/8bx 0x1955e88
0x1955e88: 0x78 0xda 0xed 0xbd 0x5f 0x6c 0x5c 0xe5
78 da is the magic number for zlib-compressed data using best compression, so this appears to be the compressed data being uncompressed. Searching for this 8-byte sequence in the trailing data identified by AspackDie, we locate the same sequence near the beginning of the data, confirming that the compressed data is loaded from the trailing data.
Continuing execution in the debugger, we note that the breakpoint is hit multiple times with different compressed data, each found successively later in the trailing data. This suggests that the trailing data contains multiple zlib-compressed files, which are read one-by-one by the application.
Extracting the data
With this in mind, we can write a simple Python script to look for zlib-compressed files within the trailing data and extract them all.
import zlib
with open('ebook.exe', 'rb') as f:
contents = f.read()
address = 0x39c94 # Offset to the first zlib-compressed file
compressed = contents[address:]
while True:
d = zlib.decompressobj()
payload = d.decompress(compressed)
payload += d.flush()
with open('out/{:08x}.bin'.format(address), 'wb') as f:
f.write(payload)
bytes_used = len(compressed) - len(d.unused_data)
# Search for the next zlib header
if b'\x78\xda' not in d.unused_data:
break
compressed = d.unused_data[d.unused_data.index(b'\x78\xda'):]
bytes_used += d.unused_data.index(b'\x78\xda')
address += bytes_used
Inspecting the result, we appear to have successfully extracted all the source files, in their various formats.
$ file out/* | head
out/00039c94.bin: PC bitmap, Windows 3.x format, 501 x 410 x 24, image size 616640, resolution 2834 x 2834 px/m, cbSize 616694, bits offset 54
out/000453e2.bin: PC bitmap, Windows 3.x format, 40 x 44 x 24, image size 5280, resolution 2834 x 2834 px/m, cbSize 5334, bits offset 54
out/00045f6a.bin: ASCII text, with CR, LF line terminators
out/0004605d.bin: HTML document, ASCII text
out/000468df.bin: HTML document, ASCII text
out/00046a47.bin: HTML document, ASCII text
out/00046b89.bin: HTML document, ASCII text
out/00046ce0.bin: GIF image data, version 89a, 512 x 608
out/00049350.bin: GIF image data, version 89a, 36 x 81
out/00049478.bin: GIF image data, version 89a, 119 x 22
$ head out/0004605d.bin
<html>
<!-- DW6 -->
<head>
<meta http-equiv="content-type" content="text/html;charset=iso-8859-1">
<title>My Ebook Title</title>
<style type="text/css">
<!--
.footer { font-size: 6.5pt; font-family: Verdana, Arial, Helvetica, sans-serif }
.footerbottom { font-size: 6.5pt; font-family: Verdana, Arial, Helvetica, sans-serif; color: #FFFFFF}
a.footerbottom:link {color: #FFFFFF}
Further dynamic analysis
We have now extracted all the source files; however, we do not know the correct filenames. Presumably, this is also stored within the trailing data and the obfuscation scheme could be determined by careful static analysis of the code. Another approach is to perform dynamic analysis to try to extract the plaintext filenames from memory.
Using the debugger, we investigate the calls to TDecompressionStream.Create. The first two times, the compressed data corresponds with the first two ‘PC bitmap’ files, which are a splash screen and logo respectively. Traversing up the call stack, we end up in functions related to display of a hardcoded splash screen image, which is not of assistance to locating the plaintext filenames of the other content.
The third call to TDecompressionStream.Create, however, is from a different location. We identify an interesting-looking function, whose decompilation is as follows.2
void FUN_004759b4(char *param_1,int *param_2)
{
// ...
iVar1 = FUN_00475900(param_1);
if (iVar1 != 0) {
// ...
piVar2 = (int *)TObject.Create((int *)VMT_40F1B0_TMemoryStream,'\x01',extraout_ECX);
// ...
TStream.CopyFrom(piVar2,DAT_00480a3c,*(int *)(iVar1 + 0x104));
// ...
TStream.SetPosition(piVar2,0);
// ...
piVar2 = TDecompressionStream.Create((int *)VMT_470388_TDecompressionStream,'\x01',piVar2);
// ...
return;
}
// ...
return;
}
Setting a breakpoint at this function in the debugger shows that param_1 points to the promising-looking string index.html, suggesting that this code is responsible for looking up filenames inside the trailing data.
(gdb)b *0x4759b4
Breakpoint 1 at 0x4759b4
(gdb)c
Continuing.
Thread 1 "064c" hit Breakpoint 1, 0x004759b4 in ?? () from /path/to/ebook_unpacked.exe
(gdb)x/s $eax
0x14a4a90: "index.html"
Relevantly, TDecompressionStream.Create is only called if the result of FUN_00475900, to which the filename is passed, is non-null. The decompilation of FUN_00475900 is also revealing.
void FUN_00475900(char *param_1)
{
// ...
iVar2 = 0;
do {
pbVar1 = (byte *)TList.Get(DAT_00480a38,iVar2);
@LStrFromString((int *)&local_10,pbVar1);
UpperCase(local_10,&pbVar1);
UpperCase(param_1,&local_14);
bVar4 = @LStrCmp((char *)pbVar1,(char *)local_14);
if (bVar4) {
TList.Get(DAT_00480a38,iVar2);
break;
}
iVar2 = iVar2 + 1;
// ...
} while (pTVar3 != (TListVT *)0x0);
// ...
}
This code loops over a TList at DAT_00480a38 (indexed by iVar2, which is incremented every iteration). A case-insensitive string comparison is performed between the filename passed in param_1, and the content of the list item. If they match, we break out of the loop.
In other words, this code loops through the TList at DAT_00480a38 to find a match for the requested filename.
We can use the debugger to inspect the contents of this TList.
(gdb)x/wx 0x480a38
0x480a38: 0x01471c10
(gdb)x/2wx 0x1471c10
0x1471c10: 0x0040ea24 0x0149ee18
(gdb)x/8wx 0x0149ee18
0x149ee18: 0x01478428 0x0147853c 0x01478688 0x014787dc
0x149ee28: 0x01478910 0x01478a88 0x01478b9c 0x01478cb0
The data at 0x1478428 is a Pascal string with a filename.

Inspecting the list entries that follow, we see that each corresponds with the filename of a source file in the ebook. Assuming that this list was built at the time of parsing the ebook data, it would be sensible to expect that the list entries would be in the same order that the files appear in the trailing data. Comparing the filenames with the content of the decompressed files, this appears to be a correct assumption, except that the first two files (corresponding to the splash screen and icon) are not listed, which makes sense given that they were hardcoded and loaded from a different function.
We can then create a GDB Python script to iterate over the elements of the list, and dump all the plaintext filenames.3
def get_memory(addr, size):
result = gdb.execute('x/{}x 0x{:x}'.format(size, addr), to_string=True)
value_string = result.split()[1]
return int(value_string[2:], 16)
def get_string(addr, length):
result = gdb.execute('x/{}bx 0x{:x}'.format(length, addr), to_string=True)
return ''.join([chr(int(b[2:], 16)) for r in result.split('\n') for b in r.split()[1:]])
with open('names.txt', 'w') as f:
for list_item in range(0x0149ee18, 0x0149f804, 4):
list_item_addr = get_memory(list_item, 'w')
list_item_len = get_memory(list_item_addr, 'b')
print(get_string(list_item_addr + 1, list_item_len), file=f)
We can then modify our decompression script to use these filenames:
import zlib
with open('ebook.exe', 'rb') as f:
contents = f.read()
with open('names.txt', 'r') as f:
names = f.read().strip().split('\n')
compressed = contents[0x39c94:] # Offset to the first zlib-compressed file
idx = 0
while True:
d = zlib.decompressobj()
payload = d.decompress(compressed)
payload += d.flush()
if idx == 0:
filename = 'splash.bmp'
elif idx == 1:
filename = 'icon.bmp'
else:
filename = names[idx - 2].replace('\\', '/')
with open('out/{}'.format(filename), 'wb') as f:
f.write(payload)
# Search for the next zlib header
if b'\x78\xda' not in d.unused_data:
break
compressed = d.unused_data[d.unused_data.index(b'\x78\xda'):]
idx += 1
This yields a fully decompressed directory of standard HTML source files and images, as required.
Standalone extraction of filenames
We could stop here; however, it would be ideal to be able to extract the filenames without reliance on the debugger. We know that one of the plaintext filenames is loaded into memory at 0x1478428, so we can set a write breakpoint on this address. We identify that the plaintext filename stored at this memory location originates from the following function.
void FUN_0047832c(int *param_1,int *param_2)
{
// ...
(**(code **)(*param_1 + 4))(param_1,&local_c,4);
// ...
if (0 < local_c) {
// ...
(**(code **)(*param_1 + 4))(param_1,local_10,local_c);
}
if (-1 < local_c + -1) {
iVar1 = 0;
iVar3 = local_c;
bVar2 = (byte)local_c;
do {
pbVar4 = (byte *)((int)local_10 + iVar1);
*pbVar4 = *pbVar4 ^ bVar2;
bVar2 = *pbVar4;
iVar1 = iVar1 + 1;
iVar3 = iVar3 + -1;
} while (iVar3 != 0);
}
// ...
}
By inspecting param_1 in the debugger, we note that it points to a structure whose first member points within the virtual method table for TFileStream.
(gdb)b *0x47832c
Breakpoint 1 at 0x47832c
(gdb)c
Continuing.
Thread 1 "0104" hit Breakpoint 1, 0x0047832c in ?? () from /path/to/ebook_unpacked.exe
(gdb)info reg
eax 0x1471c90 21437584
ecx 0x5afe24 5963300
edx 0x1471fb0 21438384
ebx 0x1471c90 21437584
[...]
(gdb)x/wx $eax
0x1471c90: 0x0040f124
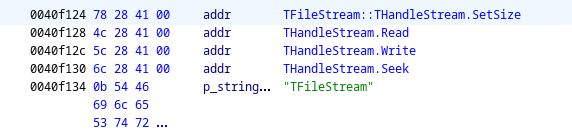
The function at (*param_1 + 4), then, is THandleStream.Read. In other words, the function reads 4 bytes from the file stream into local_c, then if local_c > 0, reads local_c bytes into local_10.
Following this, the function then iterates over all characters in local_10 and performs an XOR operation. In this context, seeing an XOR operation strongly suggests that this is the code responsible for deobfuscating filenames.
Specifically, the first character of the obfuscated input is XORed with the length to yield the first character of the plaintext filename. Subsequently, each character of the obfuscated input is XORed with the preceding character of the plaintext filename.
This could be expressed in Python follows.
def read_string():
global compressed
global address
string_len = struct.unpack('<I', compressed[0:4])[0]
string = bytearray(compressed[4:4+string_len])
xor_state = string_len & 0xff
for i in range(len(string)):
string[i] = string[i] ^ xor_state
xor_state = string[i]
compressed = compressed[4+string_len:]
address += 4 + string_len
return string.decode('ascii')
We can incorporate this into the decompression script from earlier, yielding a standalone solution for extracting the source files from the ebook.
Footnotes
-
This reverse engineering was performed on a Linux host using Wine. As compared with previous reverse engineering writeups on this blog, Ghidra and winedbg's gdb mode now play well with each other, so we can connect the Ghidra debugger to winedbg using new-ui. ↩
-
For interest's sake, the data at DAT_00480a3c points to a structure whose first member points within the VMT for TFileStream. This code, then, explains how the compressed data ends up in a TMemoryStream. ↩
-
This implementation is quite messy, by parsing the stringified output of GDB. There is probably a more appropriate way to do this using the GDB Python API. ↩